Start of topic | Skip to actions
Design of AMROC
AMROC follows the parallelization strategy proposed by M. Parashar and J. Browne within the DAGH package. All data assigned to grid patches are stored in hierarchical grid functions which are automatically distributed with respect to a global grid hierarchy. Dynamic distribution is carried out under the restriction that higher level data must reside on the same computing node as the coarsest level data (see fig. 4 on previous page). Ghost cells are employed for the setting of boundary conditions, because their application allows a similar treatment of internal and physical boundaries. In our approach distributed GridFunctions? enlarge their patches automatically by ghost cell regions of suitable size. Ghost cell regions of neighboring patches are synchronized transparently even over processor borders, whenever the AMR-method applies boundary conditions. Thus, a proper parallel synchronization of neighbors is guaranteed by the algorithm itself (see fig. 5). The use of overlapping ghost cell regions combined with the distribution strategy outlined above ensures that almost all computational operations of the parallel AMR-algorithm do not require interprocessor communication. Technical details of communication can be hidden completely against the AMR-algorithm and each GridFunction? just has to supply methods that initiate ghost cell synchronization and patch redistribution. Using the programming abstractions of AMROC's DAGH, a parallel AMR-algorithm for hyperbolic conservation laws can easily be formulated. The mere algorithm is split into a function that updates the levels recursively by employing the numerical solution routines and a function that controls the regridding procedure (see fig. 3). These functions are implemented as methods of the central AMRSolver-class. Mostly, they operate on a distributed GridFunction? attached to AMRSolver storing patch-objects for the vector of state. As mentioned above, this GridFunction? synchronizes its patches transparently over processors, when boundary conditions are applied. Additionally, it automatically fills ghost cells at internal boundaries with appropriately prolongated (locally available) coarse grid values. After setting boundary conditions, the numerical solution is computed locally. At coarse-fine interfaces the fluxes are used to calculate correction terms inside AMRFixup that ensure conservation. The correction terms are saved in GridFunctions? of lower spatial dimension that are assigned to the boundaries of fine grids. E.g. in two dimensions four of these GridFunctions? are necessary. They are initialized with the corresponding coarse grid flux, fine grid fluxes at the particular boundary are added during recursive computation (see fig. 2). Flux correction in detail depends heavily onto the specific numerical method employed. Hence, a common interface inside the AMRFixup-class guarantees the required flexibility. In particular, the wave-propagation method implemented in Clawpack is formulated as a flux-difference splitting scheme and requires a specialization which is formulated in ClpFixup?. The automatic redistribution of all GridFunctions? combined with the use of ghost cells ensures that correction terms can be computed strictly local. Only their application in form of a correction of coarse grid cell values must be done with respect to neighboring patches on other processors. Finally, coarse cell values are replaced by restricted values where finer grid patches overlap. Due to the chosen distribution strategy this operation is strictly local. When a level and all finer levels need regridding, cells are flagged for refinement locally. The refinement criterion, e.g. a combination of error estimation and approximated gradients has to be interchangeable and is consequently defined in the class AMRFlagging outside of AMRSolver. The resulting flags are kept in AMRFlagging in a integer-valued GridFunction?. Its overlap region between patches corresponds to the size of the buffer region around flagged cells. Synchronizing this GridFunction? allows a parallel execution of the cluster-algorithms that are implemented in Cluster1.h and Cluster3.h. After recomposing GridHierarchy? and all GridFunctions? as described above the newly created patches have to be initialized. While the GridFunction? for the vector of state is initialized by prolongation from the coarser level and overwritting cell values with those of already refined cells, no prolongation is necessary in case of the lower-dimensional GridFunctions? for the conservative correction term; the new patches of the integer-valued GridFunction? for the flags need not even be initialized.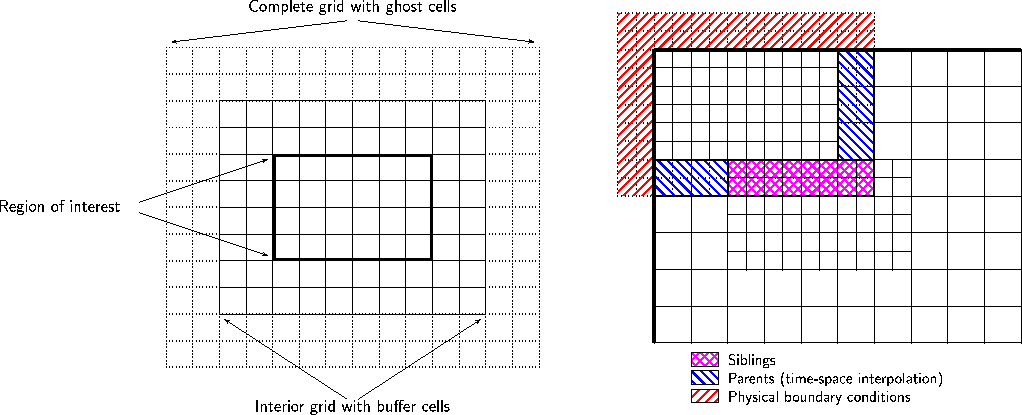 Figure 5: Parts of a refinement grid (left) and sources of values in ghost cells (right).
Figure 5: Parts of a refinement grid (left) and sources of values in ghost cells (right).
-- RalfDeiterding - 12 Dec 2004